During the early stages of the generative AI boom, cloud computing was the default choice for most organizations. Public cloud platforms allowed teams to provision GPU resources quickly, avoid upfront hardware investments, and experiment with new models without managing physical infrastructure. For startups and research teams, this approach dramatically reduced the barrier to entry.
However, the picture changes once AI moves from experimentation to production. Modern AI systems no longer process a handful of requests or occasional training jobs. They must serve millions of inference requests every day, continuously fine-tune models, manage large datasets, and deliver low-latency responses to users across multiple regions. At that scale, compute infrastructure becomes more than an operational expense—it becomes a strategic asset.
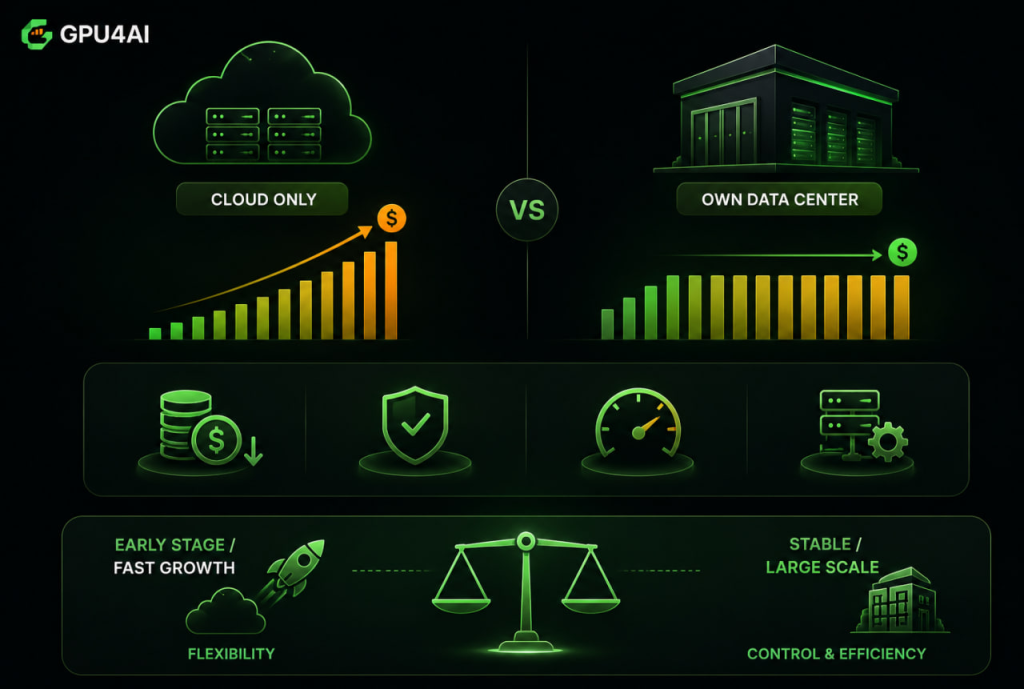
This shift explains why more AI companies are exploring the idea of building their own data centers instead of relying entirely on public cloud providers. The objective is not simply to reduce costs but also to gain greater control over performance, deployment schedules, and long-term infrastructure planning.
Why Are More AI Companies Investing in Their Own Data Centers?
One of the biggest motivations is long-term cost efficiency. Large-scale AI inference services and extended training workloads often run continuously, consuming GPU resources around the clock. Under these conditions, cloud expenses can increase significantly over time, making dedicated infrastructure financially attractive for organizations with predictable utilization.
Another factor is dependency on cloud vendors. Companies that rely exclusively on a single provider must accept pricing changes, regional GPU availability, and allocation limitations that may impact product delivery. As global demand for advanced GPUs continues to rise, obtaining immediate access to the latest hardware is not always guaranteed.
Performance consistency also plays an important role. Operating a dedicated AI infrastructure allows organizations to optimize networking, storage, GPU topology, and software stacks specifically for their own workloads. This level of control can improve throughput, reduce latency variation, and make operational costs more predictable over time.
Still, building a private AI data center is not the right decision for every company. Purchasing GPUs is only one part of the investment. Organizations must also consider power consumption, cooling systems, networking, maintenance, and specialized engineering teams. For many startups and fast-growing businesses, flexibility is often more valuable than ownership.
Build or Rent? The Real Question Is Timing
The debate is often framed as a choice between owning GPU infrastructure and using Cloud GPU services. In reality, the more important question is when each approach makes sense.
For startups that are still validating products or experimenting with different AI models, investing millions of dollars in physical infrastructure rarely provides the best return. Compute demand can change dramatically within weeks as teams iterate on architectures, adjust batch sizes, or launch new features. Predicting long-term GPU requirements at this stage is extremely difficult, making large capital investments risky.
Cloud GPU solves this problem by allowing organizations to provision computing resources only when they are needed. Development teams can scale up for model training, allocate additional GPUs during periods of heavy inference traffic, and release unused capacity immediately afterward. This pay-as-you-go model transforms large upfront capital expenditures into flexible operational costs while maintaining the ability to respond quickly to changing business needs.
For most organizations, the decision should not be driven by ideology but by utilization patterns. If GPU resources are fully occupied around the clock with highly predictable workloads, owning infrastructure may eventually become economically advantageous. If demand fluctuates frequently or products are still evolving, Cloud GPU often provides greater agility and significantly lower financial risk.
GPU4AI: Flexible AI Compute Without Massive Upfront Investment
Not every AI company needs to own a data center to build production-ready AI products. In many cases, what matters most is gaining access to the right amount of compute at the right time.
GPU4AI provides scalable GPU infrastructure optimized for modern AI workloads, including large language models, Stable Diffusion, Flux, model training, fine-tuning, and inference. Teams can provision GPU resources within minutes, select configurations that match their workloads, and expand capacity seamlessly as user demand grows.
This approach allows startups and enterprises to accelerate product development without committing to major hardware investments while preserving the flexibility to scale as their AI business evolves. Instead of spending months planning infrastructure procurement, engineering teams can focus on improving models, shipping new features, and delivering better user experiences.
FAQ
Why are more AI companies building their own data centers?
As AI workloads become larger and more predictable, owning GPU infrastructure can improve cost efficiency, performance consistency, and operational control while reducing dependence on third-party cloud providers.
Should AI startups build their own data centers?
In most cases, no. Startups typically experience rapidly changing compute requirements, making Cloud GPU a more flexible and financially efficient solution during the early stages of growth.
Can Cloud GPU replace private AI infrastructure?
For many startups and mid-sized businesses, Cloud GPU provides more than enough performance for training and inference. Larger organizations may choose hybrid architectures that combine owned infrastructure with cloud resources.
When does owning GPUs become more economical than renting?
Ownership becomes more attractive when GPU utilization remains consistently high over long periods and the total cost of ownership is lower than ongoing cloud expenses. The break-even point depends on workload characteristics, hardware lifecycle, and operational costs.
Who can benefit from GPU4AI?
GPU4AI is designed for AI startups, research teams, enterprises, and developers who need high-performance GPU resources for model training, inference, image generation, fine-tuning, and other compute-intensive AI workloads without investing heavily in physical infrastructure.
Discover GPU solutions for AI teams at:
Explore more AI infrastructure insights on our blog
————————–
About GPU4AI
GPU4AI is a GPU infrastructure platform built for AI builders, startups, and enterprises that need reliable compute without the complexity of managing hardware.
From model training and inference to AI agents and production workloads, GPU4AI provides on-demand access to enterprise-grade GPU resources designed for modern AI development.
Built with flexibility in mind, GPU4AI helps teams launch faster, scale efficiently, and optimize compute costs without investing in expensive infrastructure upfront.
Whether you’re training large language models, deploying AI applications, or running high-performance inference, GPU4AI delivers the compute foundation needed to move from experimentation to production.
Less time managing infrastructure. More time building AI.
GPU Infrastructure. Simplified for AI.


